Teams usually assume there’s a straightforward progression from prompt engineering through retrieval-augmented generation (RAG) to fine-tuning (the last rung on the ladder) when customizing large language models (LLMs). This is an easy-to-understand, frequently repeated narrative that is true for some developers but not for all teams working with LLMs in production environments.
Prompt engineering, RAG, and fine-tuning are not sequential upgrades in real-world enterprise systems. Instead, they represent different architectural methods for addressing different types of problems and introduce their own limitations and failure modes. Viewing them as a linear progression creates a false narrative that can lead to brittle systems that cannot adapt to changing requirements.
To assess the success or failure of LLM architectures in production environments, a six-dimensional framework outlines the actual constraints that affect whether an LLM system will function well or poorly in production: data privacy, latency, degree of control, update frequency, deployment target, and cost.
When LLM architecture decisions are judged
Most architectural decisions regarding LLMs are made based on assumptions rather than evaluation. It is typically only after releasing the LLM applications that teams realize that the architecture is failing to meet its intended goals. At this time, teams may face difficult questions about the performance of their released LLM: “Why is our response time inconsistent?” “Why did our costs go up this week?” “How is sensitive information showing up in our logs?”
After a poorly performing architecture choice is identified, teams often use weak excuses to justify it, such as “We chose the most advanced architecture available,” or “We are doing things the way everyone else is.” These excuses do not provide sufficient detail to help a team understand why the architecture failed to meet expectations.
A good architecture makes its trade-offs visible. A good architecture allows a team to articulate why a particular approach was selected, what benefits it provides, and the potential trade-offs. As a result, teams need to make informed decisions about which approach to select for their specific environment.
The problem with the linear ladder model for LLMs
Each of the three major approaches to customizing large language models — prompt engineering, RAG, and fine-tuning — provides a different set of capabilities and/or constraints. Each is a structural decision that will have significant implications for how the team will interact with the LLM going forward.
Many teams receive recommendations on building their LLM systems that are based on a ladder model: Start with prompt engineering; if that doesn’t work, move on to RAG; if RAG doesn’t work, move on to fine-tuning. The ladder model is attractive because it is easy to understand, offers direction and purpose for teams, and conveys a sense of progress.
However, the ladder model fails to account for the reality that teams are not judged on the sophistication of their architectures; instead, they are judged on whether their architectures violate the constraints of their environment. Teams are expected to meet performance, security, and reliability standards. If a team’s architecture prevents its LLM system from meeting these standards, it does not matter whether the team used the “latest and greatest” approach to building its application.
Many of the failures associated with LLMs occur because the architecture does not align with the problem domain’s needs. Examples of architectural failures include:
Teams experiencing high response latency and unpredictable tail times
Teams experiencing rapidly increasing operational costs
Teams experiencing data privacy violations and sensitive information risks
Teams with systems that are difficult to update without experiencing regression.
None of these failures can be addressed by moving to the next rung on the ladder. In fact, many of these failures occur specifically because a team followed the ladder without accounting for the constraints of their environment.
6 dimensions that matter in production
Production success is defined by multiple independent limits rather than a single “quality” limit. The six dimensions listed below generally define which architectures are viable.
There is no hierarchy of these dimensions. Generally, improving one dimension will degrade another. As there is no universally best configuration of these dimensions, there is only an intentional trade-off based on the system’s needs.
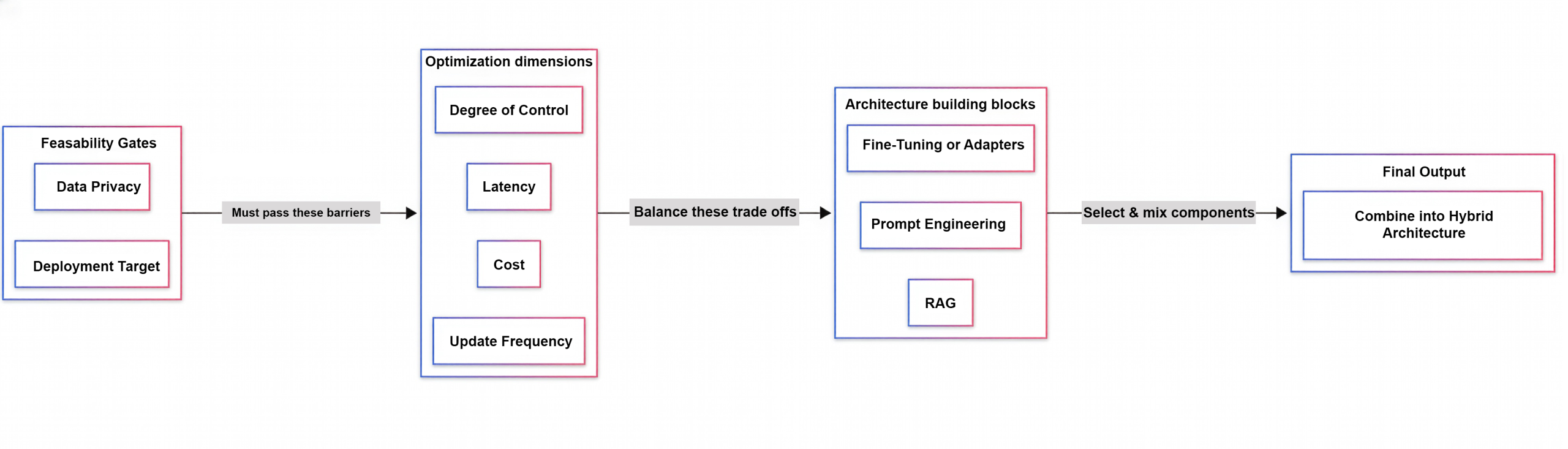
These six dimensions — data privacy, latency, degree of control, update frequency, deployment target, and cost — serve as constraints on the development of LLM architectures. The following figure illustrates how these dimensions may interact without falling into a “linear ladder” trap. The figure groups these dimensions into the initial feasibility gate (non-negotiable barrier), the optimization dimension (tunable trade-off), and resultant architecture-building block combinations that may be used as hybrid models.
Data privacy: The first feasibility barrier
Data privacy is often the first serious constraint production teams encounter and it’s generally non-negotiable. The question is not whether the model vendor is “secure.” The question is whether sensitive data can ever leave the organization’s boundaries.
Generally, prompt engineering sends the entire prompt, including user input, contextual information, etc., to an external inference provider. Even fine-tuning can create more privacy risk since the training data or derived gradients need to be sent to a tuning pipeline, thus providing longer-lived access than a single inference call.
RAG alters the privacy surface by enabling sensitive data to remain within internal systems, while only its fragments are sent to the model.
In practice, data privacy is determined by data classification. If an application handles regulated data (such as personal health information or confidential data), many architectures may quickly become infeasible unless the model is self-hosted or hosted in a controlled environment. On the other hand, if the application is public-facing and does not handle sensitive data, external APIs may be acceptable.
The key takeaway is that data privacy is a barrier, not a tunable parameter. Once data privacy is identified as a barrier to using an external inference service, the entire architecture collapses.
Latency: The constraint users notice first
Once the data privacy constraint is addressed, latency becomes the constraint users notice. Users will perceive the system as unreliable if latency is excessive or unpredictable.
The primary difference in latency among models is due to the number of architectural stages in the request path, rather than the model’s intelligence. For example, prompt engineering typically has the lowest latency since the request is only a single inference call. In addition, RAG introduces multiple stages (embedding search, retrieval, reranking, and chunk selection) that increase latency and can also generate high tail times under load. Fine-tuning typically yields fast inference paths by eliminating the need for retrieval and embedding, and by integrating them directly into the model.
Using the fastest architecture as the sole basis for selecting an architecture is a mistaken approach. More often than not, the correct design is a hybrid approach. An example of this is using a low-latency routing mechanism — a small, tuned model identifies the user’s intent, classifies the query, and then fires off a higher-latency RAG pipeline only when knowledge grounding is necessary. That type of hybrid architecture protects the user experience while enabling high-precision answers when needed.
Degree of control: Constraining behavior and knowledge
Responding quickly is irrelevant if system behavior is unstable. Degree of control, the third dimension, refers to how reliably architects can constrain the model’s behavior, outputs, and knowledge boundaries.
Prompt engineering constrains the model’s behavior primarily at the output layer. While prompt engineering can constrain the structure (such as JSON schema), formatting, and localizable behavior of the output, prompt-based control is fragile because it competes with model priors, user messages, and long-term context effects.
RAG constrains the model’s knowledge boundaries at the level of knowledge boundaries. RAG is not primarily used to make the model smarter. Rather, RAG is used to constrain what the model is allowed to know in a particular request. Therefore, RAG is particularly useful in regulatory environments, where it provides a transparent, governable knowledge path.
Fine-tuning constrains the model’s behavior to provide consistent behavior for each request. Fine-tuning defines the tone, style, reasoning patterns, classification thresholds, and domain-specific preferences that the model uses to respond to each request. It is most valuable when the desired behavior is stable and should be baked into the model, rather than being inserted at runtime.
Here again, degree of control is not one thing. Degree of control can mean:
Controlling output structure
Controlling knowledge sources
Controlling behavioral consistency
Each of these techniques constrains a different layer, and that determines what types of failures can occur.
Update frequency: The cost of keeping your system current
Update frequency describes how often a system has to add new information or modify previously acceptable behavior. Prompt engineering is useful for rapid updates because modifying a prompt is simple. But as prompts expand, maintaining them becomes hard, and versioning becomes a nightmare, along with the issues that arise when prompts interact with each other.
RAG is useful for quick, scalable updates because the knowledge base can change independently of the model. If your domain changes every week — such as policy changes, new product documentation, new HR procedures — RAG provides a clear mechanism to update the corpus rather than the model.
Fine-tuning is slow and costly to update because it involves training and validation cycles. Fine-tuning is worthwhile only when you have stable, highly valuable behavior. When you need to frequently change the underlying knowledge, fine-tuning will be a hindrance.
This is why you should follow this general rule: Keep all knowledge that changes over time outside your model. Use tuning for stable behavioral patterns; use retrieval for dynamic knowledge.
Deployment target: Where the model runs
Even though an architecture appears flawless on paper, deployment constraints can prevent implementation. Cloud API deployments can maximize speed to market. However, these deployments are subject to limitations related to privacy, regulatory compliance, and network latency.
Deployments within the virtual private cloud/on-premises environment enable data sovereignty and internal controls, but add significant complexity to both infrastructure and operations. Edge deployments often limit model size and direct development teams toward either small, tuned models or specialized inference runtimes.
Where the workload is to be deployed can limit feasibility. For example, if an organization has a data sovereignty requirement and does not permit external inference, prompt engineering via public APIs is no longer an option. For such organizations, self-hosted RAG or tuning would likely be the default, regardless of the position of either approach on the ladder.
Cost: What eliminates ‘successful’ pilot projects
Most LLM projects do not fail during the prototype phase. Most LLM projects fail after successful adoption when traffic grows and costs become non-linear.
Cost is not just “what does the model cost per token?” It can be influenced by:
The length of the prompt and the retrieved context
The class/model used and the pricing of the model provider
Concurrency/scaling strategy
Caching efficiency
GPU/CPU resource utilization for self-hosted deployments
The engineering overhead required for maintaining retrieval pipelines
While prompt engineering is often the least expensive initial approach, its cost can become unpredictable as the prompt and context sizes grow. RAG increases operational cost because the retrieval pipeline must always be running — vector databases, indexing jobs, and the reranker — but it can also decrease inference cost by enabling the use of smaller models and reducing the amount of work the LLM must do to fill in hallucinations.
Fine-tuning has very high up-front costs (training and evaluation), but it can also reduce inference costs and latency by eliminating the need to retrieve content or reducing the number of tokens required in the prompt.
The major difference here is the predictability of cost. The most dangerous systems are those that incur increased cost in proportion to their usage, such as those that frequently include large retrieved contexts or multistep LLM calls without strict budgets.
In production, cost should be considered as an architectural dimension from Day 1, not a billing shock discovered after launch.
Putting the dimensions together: A decision framework
There isn’t a single “right” solution for all applications. The appropriate architecture will depend on the relative importance of the six dimensions.
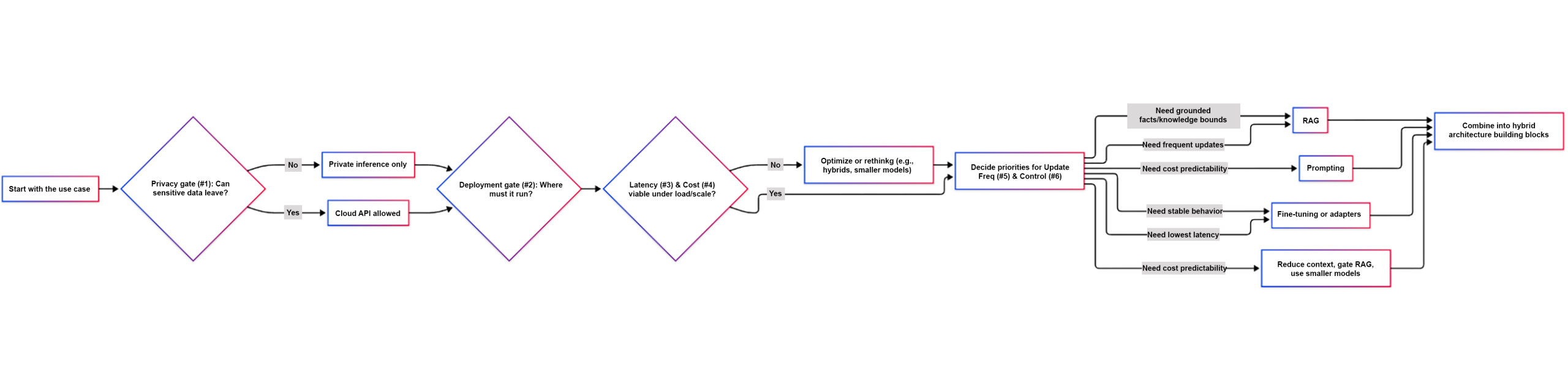
You can use the six dimensions in a particular sequence when determining which method(s) best fit your application:
Data privacy: Are you allowing sensitive information to cross the application boundary? If not, you need to eliminate any external API calls.
Deployment target: Will your application run on your required platform? Eliminate any methods that don’t support your application’s deployment target.
Latency: Can your architecture deliver the necessary low latency during periods of high load? Can your architecture meet the performance expectations of your users or customers during high-load situations?
Cost: Will your architecture be economically viable under high production traffic loads? Will your architecture remain economically viable as request volume increases?
Update frequency: How difficult is it to adapt your architecture as customer expectations evolve over time? How costly will changing your architecture be when changes occur due to evolving customer requirements?
Degree of control: To what extent do you want to control potential failure points of your architecture to minimize downtime and the associated lost revenue?
Once you have determined the relative importance of each dimension, you should create an architecture composed of multiple mechanisms that work together, rather than simply choosing a single “best” mechanism.
In real-world enterprise applications, many successful architectures are hybrids:
RAG provides governable and regularly updated knowledge.
Prompt engineering enforces structured output and task-level runtime constraints.
The six-dimensional framework explains why “prompt vs. RAG vs. fine-tuning” is the wrong question. Instead, ask yourself: Which mechanisms should I include in my architecture based upon the constraints identified above?
To make this decision-making process more tangible, the following flowchart outlines a practical approach to evaluating your LLM architecture across the six dimensions.
Conclusion
The “ladder” of developing a production LLM system — prompt engineering → RAG → fine-tuning — may appear attractive as it greatly simplifies the process of making decisions about how to develop your architecture. However, the reality is that production LLM systems are not developed by being sophisticated. Production LLM systems are developed by being constrained.
A six-dimensional framework helps identify the trade-offs involved in developing an architecture and ensures that development teams do not treat technology selection as a matter of ideology. When developing an architecture, teams can use the six dimensions to determine which mechanisms to incorporate and design hybrid systems that will withstand real user interactions.
Do not try to pursue the most advanced technique. Pursue building an application that is both safe and economically viable.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTube
channel to stream all our podcasts, interviews, demos, and more.